❖본 조사 보고서의 견적의뢰 / 샘플 / 구입 / 질문 폼❖
대규모 언어 모델(LLM) 시장 규모 및 점유율 분석 – 성장 동향 및 예측 (2026-2031)
# 1. 서론 및 보고서 개요
본 보고서는 대규모 언어 모델(LLM) 시장의 규모, 성장 동향 및 2031년까지의 전망을 상세히 분석합니다. LLM 시장은 제공 유형(소프트웨어 플랫폼 및 프레임워크 등), 배포 유형(클라우드 등), 모델 규모(70억 개 미만 매개변수 등), 양식(텍스트, 코드 등), 애플리케이션(챗봇 및 가상 비서 등), 최종 사용자 산업(BFSI 등), 그리고 지역(북미, 유럽, 아시아 등)별로 세분화되어 있으며, 시장 예측은 가치(USD) 기준으로 제공됩니다.
# 2. 시장 개요 및 주요 통계
* 연구 기간: 2020년 – 2031년
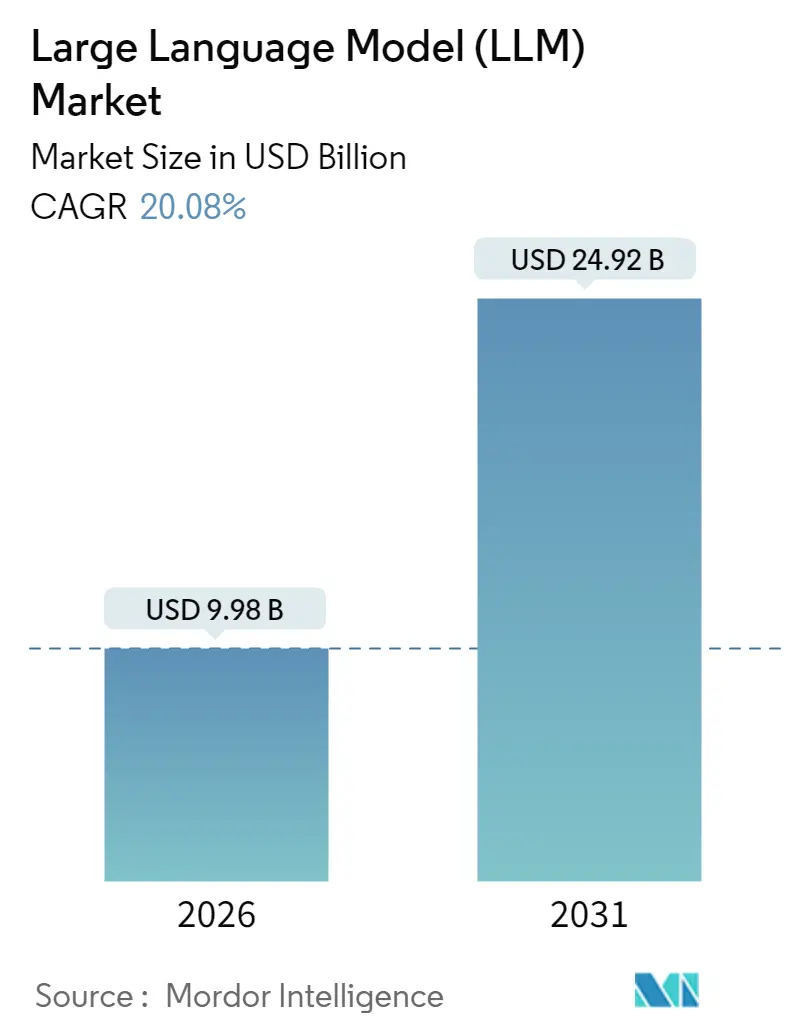
* 2026년 시장 규모: 99.8억 달러
* 2031년 시장 규모: 249.2억 달러
* 성장률 (2026년 – 2031년): 연평균 성장률(CAGR) 20.08%
* 가장 빠르게 성장하는 시장: 아시아 태평양
* 가장 큰 시장: 북미
* 시장 집중도: 중간
* 주요 기업: Alibaba Group Holding Limited, Amazon Web Services (AWS), Anthropic, Baidu, Inc., Google LLC (순서 무관)
# 3. 시장 분석
대규모 언어 모델 시장은 2025년 83.1억 달러로 평가되었으며, 2026년 99.8억 달러에서 2031년 249.2억 달러에 이를 것으로 예상되며, 예측 기간(2026-2031) 동안 20.08%의 연평균 성장률(CAGR)을 기록할 것으로 전망됩니다.
Nvidia의 Blackwell 플랫폼 및 AWS Trainium2와 같은 GPU 혁신은 소유 비용을 절감하고 규모 장벽을 제거하여 모든 규모의 기업이 자체 또는 관리형 LLM 이니셔티브를 시범 운영하도록 유도하고 있습니다. 텍스트, 이미지, 오디오를 하나의 파이프라인에서 처리하는 멀티모달 아키텍처는 연구 단계를 넘어 상업적 제공으로 전환되고 있으며, 대화형 AI를 넘어 디자인, 진단, 광고 분야로 채택이 확대되고 있습니다.
국가별 AI 규제는 구매자들이 지역적으로 훈련되거나 온프레미스 배포를 선호하도록 유도하고 있으며, 은행 및 헬스케어 분야의 도메인별 API는 환각 위험을 낮추고 규정 준수를 용이하게 하여 일반 모델을 대체하고 있습니다. 엣지 최적화 소형 언어 모델(SLM)은 스마트폰, 웨어러블 및 산업용 OEM의 디바이스 로드맵을 재편하고 있으며, 칩 공급업체 및 추론 서비스 제공업체에게 새로운 수익원을 창출하고 있습니다. 이러한 요인들은 대규모 언어 모델 시장이 집중된 클라우드 워크로드에서 계층화되고 보편적인 인텔리전스 패브릭으로 진화하는 10년을 예고합니다.
# 4. 주요 보고서 요약 (Key Report Takeaways)
* 제공 유형별: 소프트웨어 플랫폼이 2025년 대규모 언어 모델 시장 점유율의 58.35%를 차지했으며, 서비스 부문은 2031년까지 24.26%의 CAGR로 성장할 것으로 예상됩니다.
* 배포 유형별: 온프레미스 솔루션이 2025년 대규모 언어 모델 시장 규모의 51.85%로 선두를 달렸으며, 엣지/디바이스 배포는 2031년까지 27.25%의 CAGR로 성장할 것입니다.
* 모델 규모별: 1,000억 개 미만 매개변수 모델이 2025년 대규모 언어 모델 시장 점유율의 69.20%를 차지했으며, 3,000억 개 이상 매개변수 모델은 29.05%의 CAGR로 성장할 것으로 예측됩니다.
* 양식별: 텍스트 중심 모델이 2025년 매출의 67.65%를 차지했으며, 멀티모달 모델은 2031년까지 28.95%의 CAGR을 기록할 것으로 전망됩니다.
* 애플리케이션별: 챗봇 및 가상 비서가 2025년 대규모 언어 모델 시장 규모의 26.35%를 차지했으며, 코드 생성 도구는 24.75%의 CAGR로 성장할 것입니다.
* 최종 사용자 산업별: 소매 및 전자상거래가 2025년 매출의 26.75%로 선두를 달렸으며, 헬스케어 부문은 2031년까지 25.95%의 CAGR로 성장할 것입니다.
* 지역별: 북미가 2025년 매출의 31.70%를 차지했으며, 아시아 태평양은 2026년에서 2031년 사이에 31.40%의 CAGR을 기록할 것으로 예상됩니다.
# 5. 글로벌 LLM 시장 동향 및 통찰 (Drivers Impact Analysis)
주요 성장 동력과 시장에 미치는 영향은 다음과 같습니다.
| 동력 | CAGR 영향 (%) | 지리적 관련성 | 영향 기간 |
| :——————————————– | :———— | :——————————– | :————- |
| Nvidia Blackwell 및 AWS Trainium2를 통한 GPU 컴퓨팅 비용 급감 | +5.2% | 전 세계 (북미 및 동아시아 집중) | 중기 (2-4년) |
| BFSI 및 헬스케어 분야의 기업용 도메인 특화 LLM API | +4.3% | 북미 (유럽으로 확산) | 단기 (≤ 2년) |
| 국가별 AI 정책 (예: 중국 임시 규정 2024) | +3.1% | 중국, EU (전 세계적 영향) | 중기 (2-4년) |
| 임베디드 LLM 기능을 통한 SaaS 업셀링 기회 (유럽 CRM/ERP) | +2.8% | 유럽, 북미 | 단기 (≤ 2년) |
| 글로벌 AdTech 에이전시의 멀티모달 콘텐츠 수요 급증 | +2.5% | 전 세계 (북미 및 유럽 집중) | 중기 (2-4년) |
| 엣지 최적화 소형 언어 모델 (SLM)의 확산 | +2.1% | 아시아 태평양, 유럽 | 단기 (≤ 2년) |
# 6. 세부 세그먼트 분석
6.1. 제공 유형별: 소프트웨어 플랫폼 및 서비스
소프트웨어 플랫폼은 2025년 시장의 58.35%를 차지하며 LLM 배포의 핵심 기반을 제공합니다. 그러나 서비스 부문은 2031년까지 24.26%의 CAGR로 빠르게 성장할 것으로 예상됩니다. 이는 LLM의 복잡성 증가와 맞춤형 통합, 유지보수 및 컨설팅에 대한 수요 증가를 반영합니다. 기업들은 LLM의 잠재력을 최대한 활용하기 위해 풀스택 솔루션과 전문 서비스에 대한 투자를 늘리고 있습니다.
6.2. 배포 유형별: 온프레미스, 클라우드 및 엣지/디바이스
온프레미스 솔루션은 2025년 51.85%의 점유율로 시장을 선도했습니다. 이는 데이터 주권, 보안 및 규정 준수에 대한 우려가 높은 산업에서 선호되기 때문입니다. 그러나 엣지/디바이스 배포는 2031년까지 27.25%의 CAGR로 가장 빠르게 성장할 것으로 예상됩니다. 이는 개인 정보 보호, 낮은 지연 시간, 비용 효율성 및 오프라인 기능에 대한 요구가 증가함에 따라 스마트폰, 웨어러블 및 산업용 IoT 장치에 SLM이 통합되는 추세에 기인합니다.
6.3. 모델 규모별: 1,000억 개 미만, 1,000억~3,000억 개, 3,000억 개 이상 매개변수
1,000억 개 미만 매개변수 모델은 2025년 69.20%의 점유율로 시장을 지배하며, 효율성과 특정 작업에 대한 최적화로 인해 광범위하게 채택되고 있습니다. 반면, 3,000억 개 이상 매개변수 모델은 복잡한 추론, 과학적 발견 및 멀티모달 구성 사용 사례에 힘입어 29.05%의 CAGR로 가장 빠르게 성장할 것으로 예측됩니다. 제약 대기업과 클라우드 플랫폼 간의 연구 제휴는 커리큘럼 학습 및 합성 데이터를 통해 훈련 일정을 단축하여 단백질 접힘 및 재료 설계 분야의 혁신을 추진하고 있습니다.
6.4. 양식별: 텍스트, 코드, 멀티모달 등
텍스트 중심 아키텍처는 요약, 지식 관리 및 대화형 지원을 제공하며 2025년 매출의 67.65%를 차지했습니다. 그러나 고객 참여 팀, 광고 대행사 및 임상의는 텍스트와 함께 다이어그램, 이미지 및 파형을 처리하는 모델을 점점 더 요구하고 있습니다. 멀티모달 스택은 시각적 토큰 및 공동 임베딩 공간의 혁신에 힘입어 2031년까지 28.95%의 CAGR로 급증할 것입니다. 부동산 앱은 이제 여러 언어로 부동산 사진을 설명하고, 방사선 보조원은 환자 기록과 이미지를 교차 참조하여 이상 징후를 표시하는 등 LLM 시장에 새로운 영역을 열고 있습니다.
6.5. 애플리케이션별: 챗봇 및 가상 비서, 코드 생성 등
챗봇 및 가상 비서는 1차 지원, HR 헬프데스크 및 가상 컨시어지 서비스를 자동화하며 2025년 수요의 26.35%를 주도했습니다. 그러나 소프트웨어 팀의 수요가 가장 가파르게 증가하고 있습니다. 코드 생성 및 검토 도구는 함수 자동 제안, 보안 결함 감지 및 테스트 스위트 생성을 통해 개발 속도를 가속화하며 24.75%의 CAGR로 성장할 것입니다. LLM 페어 프로그래머를 사용하는 팀은 버그 감소와 출시 주기 단축을 보고하며, CFO에게 실질적인 ROI를 제공하고 LLM 시장의 확장을 이끌고 있습니다.
6.6. 최종 사용자 산업별: 소매 및 전자상거래, BFSI, 헬스케어 등
소매 및 전자상거래는 실시간 제품 Q&A, 광고 문구 및 동적 검색 재순위를 활용하여 2025년 매출의 26.75%를 차지했습니다. 금융 기관은 사기 방지 분석 및 상황별 고객 자문으로 전환하여 인력 증대 없이 교차 판매를 추진했습니다. 그러나 헬스케어 부문은 임상 LLM이 진단 추론, 문헌 합성 및 개인화된 퇴원 지침을 지원함에 따라 2031년까지 25.95%의 CAGR로 성장할 것입니다. 초기 파일럿은 퇴원 기록이 환자의 문해력 수준에 맞춰 자동 조정될 때 재입원율이 감소하는 것을 보여주며, LLM 시장 지출에 직접적인 성과 영향을 미 미치고 있습니다.
# 7. 지역 분석
7.1. 북미
북미는 벤처 자금, 대학 인재 풀 및 클라우드 GPU 공급에 힘입어 2025년 매출의 31.70%를 차지하며 가장 큰 시장입니다. 이 지역의 기업들은 자산 관리, 종양학 의사 결정 지원 및 법률 연구를 위한 도메인별 비서를 가장 먼저 배포했습니다. 주 차원의 개인 정보 보호 법안과 알고리즘 편향에 대한 연방 정부의 관심은 설명 가능성 모듈에 대한 수요를 촉진하지만, 전반적인 정책은 혁신 친화적입니다. 하이퍼스케일러의 AI 지원 데이터 센터의 지속적인 확장은 지역 처리량을 뒷받침하여 LLM 시장이 상당한 북미 핵심을 유지하도록 보장합니다.
7.2. 아시아 태평양
아시아 태평양은 정부가 주권 모델 이니셔티브를 지원하고 언어 다양성이 현지 검사 지점을 촉진함에 따라 31.40%의 가장 빠른 CAGR을 기록할 것입니다. 중국의 임시 조치는 온쇼어 훈련을 의무화하여 국내 가속기 설계 및 클라우드 서비스를 활성화하고 있습니다. 일본은 2025년 디지털 가든 전략에 따라 고영향 AI를 장려하고 있으며, 인도의 IndiaAI Mission은 스타트업에 공개 데이터 세트와 GPU 크레딧을 제공합니다. 엣지 네이티브 소형 언어 모델은 인도네시아 및 필리핀과 같은 스마트폰 중심 시장에서 반향을 일으키며 농촌 지역 커버리지를 확장하고 LLM 시장을 확대하고 있습니다.
7.3. 유럽
유럽은 EU AI Act 하에 야망과 신중함의 균형을 이룹니다. 기업들은 데이터 상주와 확장성을 조화시키기 위해 하이브리드 배포를 추구하며, 민감한 워크로드에는 프라이빗 클러스터를 사용하고 버스트 용량에는 퍼블릭 클라우드를 사용합니다. 스페인, 프랑스, 이탈리아는 지속 가능성 목표를 충족하기 위해 종종 재생 에너지로 구동되는 AI 지원 서버 팜을 늘리고 있습니다. SaaS 업셀링 물결이 여기에서 두드러지며, ERP 공급업체는 현지 감사 표준을 충족하는 다국어 채팅 및 송장 조정 기능을 추가하고 있습니다.
# 8. 경쟁 환경
상위 5개 공급업체가 실리콘에서 소프트웨어에 이르는 통합 스택을 기반으로 매출의 85% 이상을 차지합니다. Nvidia는 2025년 초 소프트웨어 오케스트레이션 자산을 인수하여 원스톱 AI 플랫폼 제공업체로서의 입지를 강화했습니다. Microsoft는 OpenAI 및 신흥 연구소 xAI와의 파트너십을 심화하여 모델 위험을 분산하고 고객 매력을 확대했습니다. Oracle은 Microsoft 및 OpenAI와 협력하여 멀티클라우드 AI 지역을 제공하며 규정 준수와 탄력적인 GPU 규모를 결합했습니다.
오픈소스 경쟁자 및 지역 전문 기업들은 상업적 라이선스 기준보다 낮은 비용으로 상업적 라이선스 기준에 필적하는 효율적인 체크포인트를 출시하여 강세를 보이고 있습니다. Anthropic의 Claude 4는 다단계 추론 벤치마크를 추진했으며, Meta 기반 모델의 혼합 정밀 미세 조정은 커뮤니티 리더보드를 지배하고 있습니다. 한국과 독일의 통신사들은 주권 AI 클라우드를 구축하여 규제된 워크로드를 확보하고 미국 하이퍼스케일러로부터 점유율을 빼앗으려 하고 있습니다. 수직 데이터, 도메인 평가 스위트 및 신속한 배포 API를 패키징하는 스타트업은 보험, 물류 및 광업 분야에서 계약을 확보하여 LLM 시장에 새로운 역동성을 불어넣고 있습니다.
순수한 모델 가중치보다는 전략적 제휴가 이제 기업 RFP를 결정합니다. 참조 아키텍처, 비용 시뮬레이터 및 규정 준수 대시보드를 제공하는 공급업체는 조달에서 견인력을 얻습니다. 에너지 효율성, 공급망 탄력성 및 투명한 사용 지표는 마스터 서비스 계약에서 중요하게 다루어지며, 구매자 플레이북이 성숙하고 있음을 시사합니다. 오픈 가중치가 독점적 해자를 침식함에 따라, 기존 기업들은 배포 도구, 안전 통합 및 글로벌 유통 역량으로 점점 더 차별화하고 있습니다.
# 9. 최근 산업 동향
* 2025년 5월: Anthropic, 개선된 다단계 추론 기능을 갖춘 Claude 4 모델 출시.
* 2025년 5월: Microsoft, Anthropic 및 xAI의 기술을 통합하여 AI 스택 다각화.
* 2025년 5월: OpenAI, 소프트웨어 개발 작업을 위한 에이전트 Codex 도입.
* 2025년 4월: Google, AI 에이전트용 Anthropic의 상호 운용성 프로토콜 채택.
* 2025년 4월: Nvidia, 풀스택 AI 제어를 확장하는 인수 발표.
* 2025년 3월: EY India, LLAMA 3.1-8B 기반의 미세 조정된 BFSI LLM 공개.
* 2025년 3월: Google, Anthropic에 투자하여 AI 파트너십 강화.
* 2025년 3월: Nebius 및 YTL, Blackwell Ultra GPU 인스턴스 출시.
보고서 요약: 대규모 언어 모델(LLM) 시장 분석
본 보고서는 대규모 언어 모델(LLM) 시장에 대한 포괄적인 분석을 제공합니다. LLM 시장은 10억 개 이상의 매개변수를 가진 트랜스포머 기반 모델의 학습, 배포 및 활용을 지원하는 소프트웨어 플랫폼, 프레임워크, 그리고 관련 통합 및 미세 조정 서비스에서 발생하는 수익으로 정의됩니다. 이는 API 호출당 과금, 구독 또는 기업 라이선스 형태로 수익이 창출되며, 독립형 컴퓨터 비전 생성 모델이나 GPU, ASIC, 서버 판매는 범위에서 제외됩니다.
시장 규모 및 성장 전망:
LLM 시장은 2026년 99억 8천만 달러 규모에서 2031년까지 249억 2천만 달러에 이를 것으로 전망됩니다. 아시아 태평양 지역은 정부 투자 및 다국어 모델 수요로 2031년까지 연평균 31.40%의 가장 빠른 성장이 예상됩니다. 엣지 모델은 낮은 지연 시간, 강화된 개인 정보 보호, 대역폭 비용 절감 효과로 연평균 27.25%의 성장률을 기록하며 중요한 동력입니다. 헬스케어 부문은 임상 의사 결정 지원, 연구 가속화, 환자 참여 애플리케이션으로 연평균 25.95%의 가장 적극적인 투자가 예측됩니다.
주요 시장 동인:
시장의 주요 동인은 Nvidia Blackwell 및 AWS Trainium2를 통한 GPU 컴퓨팅 비용 급락, BFSI 및 헬스케어(북미) 분야의 엔터프라이즈급 도메인 특화 LLM API 확산입니다. 중국 2024년 임시 규정 등 국가별 AI 정책은 현지 학습을 의무화하며, 유럽 CRM/ERP 시장에서는 LLM 기능 내장 SaaS 제품의 상향 판매 기회가 증가합니다. 전 세계 애드테크 에이전시의 멀티모달 콘텐츠 수요 급증과 스마트폰용 엣지 최적화 소형 언어 모델(20억 개 미만 매개변수) 등장은 시장 확장에 기여합니다.
주요 시장 제약:
반면, 추론 에너지 비용(1천 토큰당 0.12달러) 상승은 중소기업(남미)의 LLM 도입을 제한하며, EU AI Act의 고위험 규제 준수 비용은 기업에 부담입니다. 아프리카 언어 다국어 학습 데이터 부족과 하이퍼스케일러의 H100 GPU 공급 통제는 온프레미스 고성능 컴퓨팅(HPC) 구축을 제약합니다.
시장 세분화:
보고서는 시장을 제공 방식(소프트웨어 플랫폼 및 프레임워크, 서비스), 배포 방식(클라우드, 온프레미스, 엣지), 모델 크기(매개변수: 70억 개 미만, 70억~700억 개, 700억~3천억 개, 3천억 개 초과), 모달리티(텍스트, 코드, 이미지, 오디오, 멀티모달), 애플리케이션(챗봇, 코드 생성, 콘텐츠 생성, 고객 서비스 자동화, 언어 번역, 감성 분석, 자율 에이전트), 최종 사용자 산업(BFSI, 헬스케어, 소매, 미디어, IT 및 통신, 교육, 제조, 정부 및 국방), 그리고 지역(북미, 유럽, 아시아 태평양, 남미, 중동 및 아프리카)별로 세분화하여 분석합니다. 기업들은 비용 효율적 추론을 위해 1천억 개 미만 매개변수 모델을 선호하나, 3천억 개 초과 모델은 복잡한 추론 작업에서 지배적이며 연평균 29.05%로 성장합니다.
경쟁 환경 및 주요 기업:
경쟁 환경 분석에는 시장 집중도, 전략적 움직임, 시장 점유율 분석이 포함됩니다. 주요 기업으로는 OpenAI, Google, Anthropic, Microsoft, Amazon Web Services, Meta Platforms, NVIDIA, IBM, Alibaba Group, Baidu, Tencent Holdings, Huawei Technologies, Cohere, AI21 Labs, Mistral AI, Stability AI, Databricks, Snowflake, ByteDance, Yandex, Samsung SDS, Oracle 등이 있습니다.
연구 방법론:
본 보고서는 1차 연구(AI 제품 리더, 클라우드 운영 아키텍트, 규제 준수 담당자, 학계 연구원 인터뷰)와 2차 연구(미국 특허청, OECD, WTO, EU AI Act 관련 공개 자료, 기업 재무 보고서, 개발자 컨퍼런스 기록, 무역 협회 브리핑, 구독 데이터베이스 등)를 병행하여 수행되었습니다. 시장 규모 산정 및 예측은 상향식 및 하향식 접근 방식을 혼합하며, 사용자당 월별 토큰 생성량, 클라우드/온프레미스 배포 비중, 평균 매개변수 수, 미세 조정 서비스 계약 성장률, 지역별 AI 정책 인센티브 등 핵심 변수를 고려합니다. 데이터는 이상 징후 검사 및 다단계 동료 검토를 거쳐 검증되며, 보고서는 매년 업데이트되고 주요 변화 발생 시 중간 수정됩니다. 규제는 현지 학습 장려, 규제 준수 비용 증가, 설명 가능하고 지역적으로 호스팅되는 모델로 구매자 선택을 유도합니다.
1. 서론
- 1.1 연구 가정 및 시장 정의
- 1.2 연구 범위
2. 연구 방법론
3. 요약
4. 시장 환경
- 4.1 시장 개요
-
4.2 시장 동인
- 4.2.1 Nvidia Blackwell 및 AWS Trainium2를 통한 GPU 컴퓨팅 비용의 급격한 하락
- 4.2.2 BFSI 및 헬스케어 분야의 기업용, 도메인별 LLM API (북미)
- 4.2.3 현지 학습을 강제하는 국가 AI 정책 (예: 중국 임시 규정 2024)
- 4.2.4 임베디드 LLM 기능으로 인한 SaaS 상향 판매 기회 (유럽 CRM/ERP)
- 4.2.5 글로벌 애드테크 에이전시의 멀티모달 콘텐츠 수요 급증
- 4.2.6 스마트폰을 위한 엣지 최적화 소형 언어 모델 (20억 매개변수 미만)
-
4.3 시장 제약
- 4.3.1 추론 에너지 비용 증가 (USD0.12/1K 토큰)로 인한 중소기업 채택 제한 (남미)
- 4.3.2 EU AI 법 고위험 규정 준수 오버헤드
- 4.3.3 아프리카 언어에 대한 다국어 학습 데이터 부족
- 4.3.4 H100 GPU 공급에 대한 하이퍼스케일러 통제로 인한 온프레미스 HPC 제약
- 4.4 산업 생태계 분석
- 4.5 기술 전망
-
4.6 포터의 5가지 경쟁 요인 분석
- 4.6.1 신규 진입자의 위협
- 4.6.2 구매자의 교섭력
- 4.6.3 공급자의 교섭력
- 4.6.4 대체재의 위협
- 4.6.5 경쟁 강도
5. 시장 규모 및 성장 예측 (가치)
-
5.1 제공 방식별
- 5.1.1 소프트웨어 플랫폼 및 프레임워크
- 5.1.1.1 범용 LLM 플랫폼
- 5.1.1.2 도메인별 LLM 솔루션
- 5.1.2 서비스
- 5.1.2.1 컨설팅 및 시스템 통합
- 5.1.2.2 미세 조정 및 맞춤화
- 5.1.2.3 관리형 추론 및 호스팅
-
5.2 배포 방식별
- 5.2.1 클라우드 (퍼블릭 및 프라이빗)
- 5.2.2 온프레미스/전용 AI 클러스터
- 5.2.3 엣지/장치 내장형
-
5.3 모델 크기별 – 매개변수
- 5.3.1 7 B 미만 매개변수
- 5.3.2 7 – 70 B 매개변수
- 5.3.3 70 – 300 B 매개변수
- 5.3.4 300 B 초과 매개변수
-
5.4 모달리티별
- 5.4.1 텍스트
- 5.4.2 코드
- 5.4.3 이미지
- 5.4.4 오디오
- 5.4.5 멀티모달
-
5.5 애플리케이션별
- 5.5.1 챗봇 및 가상 비서
- 5.5.2 코드 생성 및 검토
- 5.5.3 콘텐츠 및 미디어 생성
- 5.5.4 고객 서비스 자동화
- 5.5.5 언어 번역 및 현지화
- 5.5.6 감성 및 의도 분석
- 5.5.7 자율 에이전트 및 RPA
-
5.6 최종 사용자 산업별
- 5.6.1 BFSI
- 5.6.2 헬스케어 및 생명 과학
- 5.6.3 소매 및 전자상거래
- 5.6.4 미디어 및 엔터테인먼트
- 5.6.5 정보 기술 및 통신
- 5.6.6 교육
- 5.6.7 제조
- 5.6.8 정부 및 국방
-
5.7 지역별
- 5.7.1 북미
- 5.7.1.1 미국
- 5.7.1.2 캐나다
- 5.7.1.3 멕시코
- 5.7.2 유럽
- 5.7.2.1 독일
- 5.7.2.2 영국
- 5.7.2.3 프랑스
- 5.7.2.4 이탈리아
- 5.7.2.5 스페인
- 5.7.2.6 기타 유럽
- 5.7.3 아시아-태평양
- 5.7.3.1 중국
- 5.7.3.2 일본
- 5.7.3.3 대한민국
- 5.7.3.4 인도
- 5.7.3.5 동남아시아
- 5.7.3.6 기타 아시아-태평양
- 5.7.4 남미
- 5.7.4.1 브라질
- 5.7.4.2 기타 남미
- 5.7.5 중동 및 아프리카
- 5.7.5.1 중동
- 5.7.5.1.1 아랍에미리트
- 5.7.5.1.2 사우디아라비아
- 5.7.5.1.3 기타 중동
- 5.7.5.2 아프리카
- 5.7.5.2.1 남아프리카 공화국
- 5.7.5.2.2 기타 아프리카
6. 경쟁 환경
- 6.1 시장 집중도
- 6.2 전략적 움직임
- 6.3 시장 점유율 분석
-
6.4 기업 프로필 (글로벌 개요, 시장 개요, 핵심 부문, 재무, 전략 정보, 시장 순위/점유율, 제품 및 서비스, 최근 개발 포함)
- 6.4.1 OpenAI LP
- 6.4.2 Google LLC
- 6.4.3 Anthropic PBC
- 6.4.4 Microsoft Corp.
- 6.4.5 Amazon Web Services Inc.
- 6.4.6 Meta Platforms Inc.
- 6.4.7 NVIDIA Corp.
- 6.4.8 IBM Corp.
- 6.4.9 Alibaba Group Holding Ltd.
- 6.4.10 Baidu Inc.
- 6.4.11 Tencent Holdings Ltd.
- 6.4.12 Huawei Technologies Co. Ltd.
- 6.4.13 Cohere Inc.
- 6.4.14 AI21 Labs Ltd.
- 6.4.15 Mistral AI SAS
- 6.4.16 Stability AI Ltd.
- 6.4.17 Databricks Inc.
- 6.4.18 Snowflake Inc.
- 6.4.19 ByteDance Ltd.
- 6.4.20 Yandex LLC
- 6.4.21 Samsung SDS Co. Ltd.
- 6.4.22 Oracle Corp.
7. 시장 기회 및 미래 전망
❖본 조사 보고서에 관한 문의는 여기로 연락주세요.❖
거대 언어 모델(Large Language Model, LLM)은 방대한 양의 텍스트 데이터를 학습하여 인간과 유사한 언어를 이해하고 생성하는 딥러닝 기반의 인공지능 모델을 의미합니다. 수십억에서 수천억 개에 달하는 매개변수를 가지고 있으며, 주로 트랜스포머(Transformer) 아키텍처를 기반으로 구축됩니다. 이러한 모델은 문맥을 파악하고, 복잡한 질문에 답하며, 요약, 번역, 창의적인 글쓰기 등 다양한 언어 관련 작업을 수행하는 데 탁월한 능력을 보여줍니다. 특히, 사전 학습(pre-training) 단계에서 인터넷상의 대규모 텍스트 코퍼스를 학습하여 일반적인 언어 지식과 패턴을 습득하며, 이후 특정 작업을 위해 미세 조정(fine-tuning)되거나 프롬프트 엔지니어링을 통해 활용됩니다.
거대 언어 모델의 유형은 주로 아키텍처와 학습 방식에 따라 구분됩니다. 대표적으로는 GPT(Generative Pre-trained Transformer) 시리즈와 같이 텍스트 생성에 특화된 디코더 전용(decoder-only) 모델이 있습니다. 이들은 주어진 입력에 이어지는 텍스트를 예측하며 새로운 콘텐츠를 생성하는 데 강점을 보입니다. 반면, BERT(Bidirectional Encoder Representations from Transformers)와 같이 텍스트 이해에 중점을 둔 인코더 전용(encoder-only) 모델도 존재하며, 문장 분류, 개체명 인식 등 분석 작업에 주로 활용됩니다. 또한, T5(Text-to-Text Transfer Transformer)와 같이 인코더-디코더(encoder-decoder) 구조를 모두 사용하여 번역이나 요약과 같은 시퀀스-투-시퀀스(sequence-to-sequence) 작업에 적합한 모델도 있습니다. 최근에는 특정 도메인에 특화된 모델이나, 오픈 소스로 공개되어 접근성을 높인 모델들도 다양하게 등장하고 있습니다.
이러한 거대 언어 모델은 광범위한 분야에서 활용되고 있습니다. 가장 대표적인 활용 사례는 챗봇 및 가상 비서로, 자연스러운 대화를 통해 고객 서비스, 정보 제공, 예약 등의 업무를 처리합니다. 또한, 콘텐츠 생성 분야에서는 기사 작성, 마케팅 문구 생성, 소설 및 시 창작 등 창의적인 글쓰기를 지원하며 생산성을 향상시킵니다. 교육 분야에서는 개인 맞춤형 학습 자료를 제공하거나 질문에 답하는 튜터 역할을 수행할 수 있으며, 번역 서비스의 정확도를 높이는 데도 기여합니다. 프로그래밍 코드 생성 및 디버깅 지원, 의료 분야에서의 진단 보조, 법률 문서 분석 등 전문적인 영역에서도 그 활용 가치가 점차 확대되고 있습니다.
거대 언어 모델의 발전은 여러 관련 기술의 진보와 밀접하게 연결되어 있습니다. 핵심적으로는 트랜스포머 아키텍처의 혁신이 모델의 성능을 비약적으로 향상시켰습니다. 또한, 모델 학습에 필요한 방대한 데이터를 수집하고 정제하는 기술, 그리고 이러한 대규모 모델을 효율적으로 학습시키기 위한 고성능 컴퓨팅(GPU, TPU) 및 분산 학습 기술이 필수적입니다. 모델의 성능을 특정 작업에 최적화하는 미세 조정(fine-tuning) 기법과, 인간의 피드백을 통해 모델의 응답을 개선하는 강화 학습(Reinforcement Learning from Human Feedback, RLHF) 또한 중요한 관련 기술입니다. 최근에는 외부 지식 베이스와 연동하여 모델의 환각(hallucination) 현상을 줄이고 정확도를 높이는 검색 증강 생성(Retrieval Augmented Generation, RAG) 기술과 이를 위한 벡터 데이터베이스 기술도 주목받고 있습니다.
현재 거대 언어 모델 시장은 급격한 성장과 치열한 경쟁을 보이고 있습니다. 2022년 말 ChatGPT의 등장을 기점으로 대중의 인식이 크게 높아졌으며, OpenAI, Google, Microsoft, Anthropic 등 글로벌 빅테크 기업들이 선두를 다투고 있습니다. 국내에서도 네이버의 하이퍼클로바X, 카카오의 코GPT, LG AI 연구원의 엑사원 등 자체적인 거대 언어 모델을 개발하며 경쟁에 참여하고 있습니다. 시장은 단순히 모델의 크기를 키우는 것을 넘어, 특정 산업이나 기업 환경에 최적화된 맞춤형 모델, 비용 효율적인 경량 모델, 그리고 멀티모달(multimodal) 기능을 통합한 모델 개발에 집중하고 있습니다. 또한, 모델의 윤리적 사용, 데이터 프라이버시, 보안 문제에 대한 사회적 논의와 규제 움직임도 활발하게 진행되고 있습니다.
미래 거대 언어 모델의 전망은 매우 밝습니다. 첫째, 모델의 성능과 지능은 지속적으로 향상될 것으로 예상됩니다. 특히, 추론 능력과 복잡한 문제 해결 능력이 강화되어 더욱 정교하고 신뢰할 수 있는 결과물을 제공할 것입니다. 둘째, 텍스트를 넘어 이미지, 음성, 비디오 등 다양한 형태의 데이터를 이해하고 생성하는 멀티모달 LLM이 주류로 자리 잡을 것입니다. 이는 인간과 더욱 자연스럽게 상호작용하는 AI 시스템의 등장을 가능하게 할 것입니다. 셋째, 모델의 경량화 및 효율화 기술이 발전하여 더 적은 자원으로도 고성능을 발휘하는 모델이 등장하고, 이는 온디바이스(on-device) AI의 확산을 가속화할 것입니다. 마지막으로, 거대 언어 모델은 단순한 도구를 넘어 자율적인 AI 에이전트로서 다양한 산업과 일상생활에 깊숙이 통합되어 혁신을 주도할 것으로 기대됩니다. 동시에, AI의 책임감 있는 개발과 활용을 위한 윤리적, 사회적 프레임워크 구축의 중요성 또한 더욱 커질 것입니다.